Intro
The goal of this lab was to build models showing sand mining suitability and risk in Trempealeau County, WI. To build these models many raster geoprocessing tools were used. After making both the suitability model and the risk model for Trempealeau County, they can be combined to figure out the best locations for sand mining with the smallest impacts on the environment and on the people residing there.Methods
To make the models for this exercise numerous raster tools and criteria were established. Most commonly the first step would be to convert the feature to a raster so analysis could be performed. If the feature was already a raster then I could skip right to the reclassify step, where the variables were set on classification for that raster. A couple of the other steps required further analysis with tools such as project raster, slope, block statistics, and topo to raster. The combination of all these tools with raster calculator at the end, resulted in the final product for this exercise.
 |
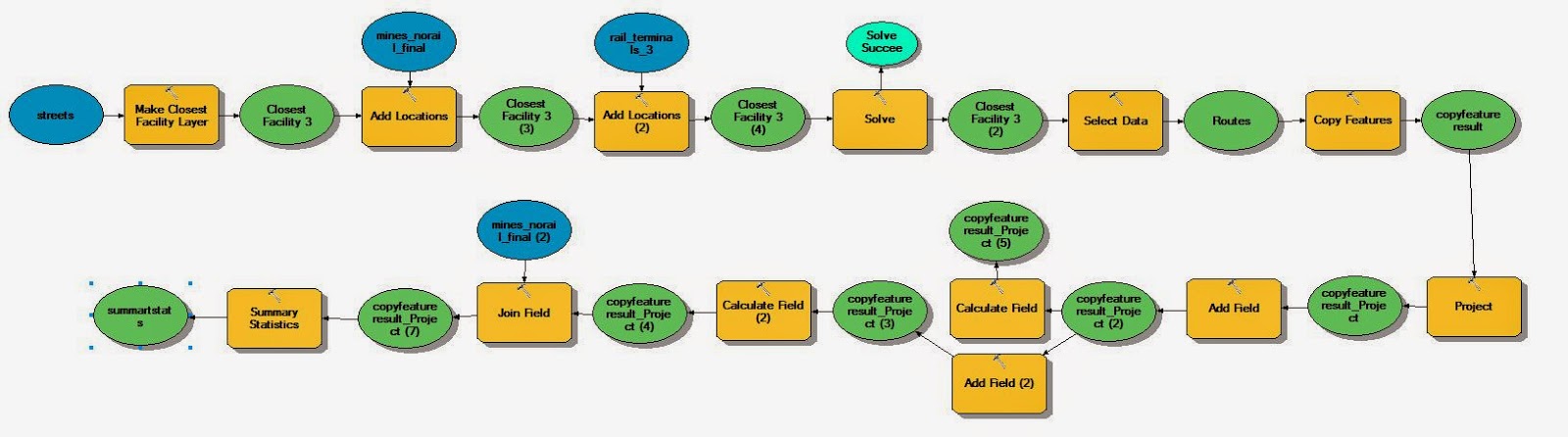
| Figure 1. This is the model for the first half of part one of the exercise it consists of making the suitability model for sand mining in Trempealeau County, WI. |
 |
| Figure 2. The model from the second half of part one shows the workflow for creating a risk model for sand mining in Trempealeau County, WI. |
In the second half of the exercise proximity to streams, farmland, residential areas, schools, and the flood plain, and the view from prime recreational areas were the criteria used as a basis for the risk model.
 |
| Figure 3. A weighted index model used to weight one of the factors in modeling |
Results and Discussion
The nine maps below are objectives that were completed in order to find out the risk and suitability of sand mining in Trempealeau County, WI. Each map has either two or three classifications. The classifications are
Green = Suitable
Yellow = Somewhat Suitable
Red = Not Suitable
These colors also allude to the risk of sand mining in the maps that that idea pertains to.
By looking at these maps it becomes clear that the best place for possible sand mining is west central Trempealeau County, although this isn't the only place, just the largest area. Based on my on interpretation it seems the biggest factors in this are the distance to railroad terminals, because there is only one and it is on the far western side. The other big factor I feel is zoning in the county. By looking at the zoning map you can see a large green swathe through the west central part of the county.









Conclusion
Using the knowledge and tools acquired throughout my experience in GIS to complete an exercise like this makes me feel more confident entering the workforce. The advanced raster analysis tools in ArcGIS are very powerful and are a very helpful way to show what needs to be shown. Even though this exercise doesn't hold any real weight as far as classifications, I still feel like it is somewhat accurate to where sand mines would need to be located. It goes to show how much thought can be put into building one of these mines and the implications if all criteria are not met. I think one interesting thing to do would be to use our geocoded mines to see if they follow our suitability and risk models.