Intro
The goal of this lab was to use network analysis, python scripting, and data flow modeling to carry out the steps of the lab automatically. This does require some time to set up and get running properly, but after everything runs on its own. Network analysis is a powerful tool that allows for many different types of routing, in this case to the nearest facility. Network analysis is a key tool for logistics in many companies and is a smart way to figure out the most efficient route. Python scripting is another great way to save yourself some time and let the scripts run the tools and create things for you. Lastly data flow modeling is another piece of the same pie that allows the displaying of a process and then streamlines it. In this instance we created a python script which narrowed our data by the criteria provided, and created some feature classes. We then made a data flow model, which we used to run network analysis and provide us with some statistics on the effects of sand trucks on roads.
Methods
First the script was written in python to scale down our data based on criteria. The criteria were that we didn't want to include any mines that have a railroad loading station, or ones that are within 1.5km of a railroad, because if that's the case they would have built a spur. Those criteria were met with the script and new feature classes were made based on those criteria. More information on this part of the lab can be found in my last post.
Network analyst is used to do efficient route modeling. The network analyst tools were used in this lab to find the nearest facility, the facilities being the rail terminals in Wisconsin, as well as in Winona, MN. The incidents in the network analyst tool were labeled as incidents. The data used in the network analysis were from a couple sources. The network dataset that contains the roads came from ESRI streetmap data, the mine data came from the Wisconsin DNR, and the rail terminal data was provided by the Department of Transportation.
The data flow model used in this lab allowed the automation of the routes, creation of new fields, and also the calculation and summarizing of said fields. The two fields that were added were "Miles" and "Cost". To calculate the miles field I took the shape length of each route, which is in meters because of the projection, and divided it by 1,609 (how many meters are in a mile). This equation gave me the number of miles. In the second calculate field box I calculated the impact in dollars of having sand trucks drive on roads in Wisconsin by county. The trucks took 50 trips there and back, meaning 100 total trips. The impact on roads per mile was 2.2 cents. The equation for this calculation was ((100*[Miles])*2.2/100). By dividing the total by 100 I got the number in dollars instead of cents.
Network analyst is used to do efficient route modeling. The network analyst tools were used in this lab to find the nearest facility, the facilities being the rail terminals in Wisconsin, as well as in Winona, MN. The incidents in the network analyst tool were labeled as incidents. The data used in the network analysis were from a couple sources. The network dataset that contains the roads came from ESRI streetmap data, the mine data came from the Wisconsin DNR, and the rail terminal data was provided by the Department of Transportation.
The data flow model used in this lab allowed the automation of the routes, creation of new fields, and also the calculation and summarizing of said fields. The two fields that were added were "Miles" and "Cost". To calculate the miles field I took the shape length of each route, which is in meters because of the projection, and divided it by 1,609 (how many meters are in a mile). This equation gave me the number of miles. In the second calculate field box I calculated the impact in dollars of having sand trucks drive on roads in Wisconsin by county. The trucks took 50 trips there and back, meaning 100 total trips. The impact on roads per mile was 2.2 cents. The equation for this calculation was ((100*[Miles])*2.2/100). By dividing the total by 100 I got the number in dollars instead of cents.
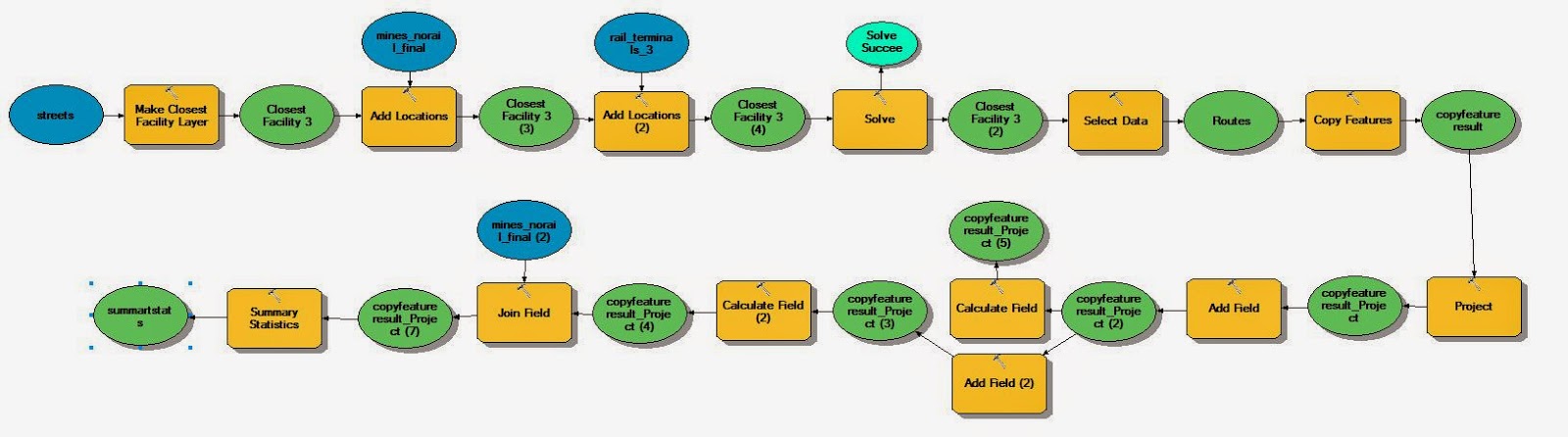 |
| Figure 1. The model used in exercise 7 to calculate the impact in dollars on Wisconsin roads. |
Results and Discussion
The results shown below are all hypothetical and should not be used to make any decisions regarding policymaking, and should also not be shown in any publications.
Figure 2. Below shows a map of the quickest routes from sand mines to rail terminals. An observation can be made that some of the routes go into Minnesota and use their roads. This means there are no impacts on Wisconsin roads, as long as the mine uses the most efficient route. In these cases it makes more sense economically to use a highway, then stay in Wisconsin and take back roads. As you can see the rail terminals in Wood, Trempealeau, and Chippewa counties have numerous mines that utilize them. This can be seen in the frequency field of figure 3. What figure 3. also shows is that those three counties mentioned are not the highest on the cost field ranking. This is due in part to how short the routes are for most of the mines in the counties. In counties like Burnett and Barron the frequency is lower, but the trips are a lot longer. Should frac sand mines have to pay for the impacts they have on Wisconsin roads? Should more rail spurs be made to prevent the impact on roads? These are questions that the Wisconsin DOT and the state government will have to ponder as more and more mines become active in the state.
 |
| Figure 2. Map of routes from sand mines to rail terminals. |
 |
Figure 3. Table of frequency of routes per county as well as cost of trucking on roads by county.Conclusions
After doing this analysis many questions come to mind on how the state plans to deal with the sand mines, especially since in the coming years there will only be more and more becoming active. Just by doing this hypothetical exercise one can see the impacts are happening to some degree. Not to mention the other effects the excessive trucking has like air pollution and noise pollution. network analyst can play a big role in answering some of these questions and will most likely be used when the state does decide to make a decision on this topic.
|




